Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Last updated 19 setembro 2024
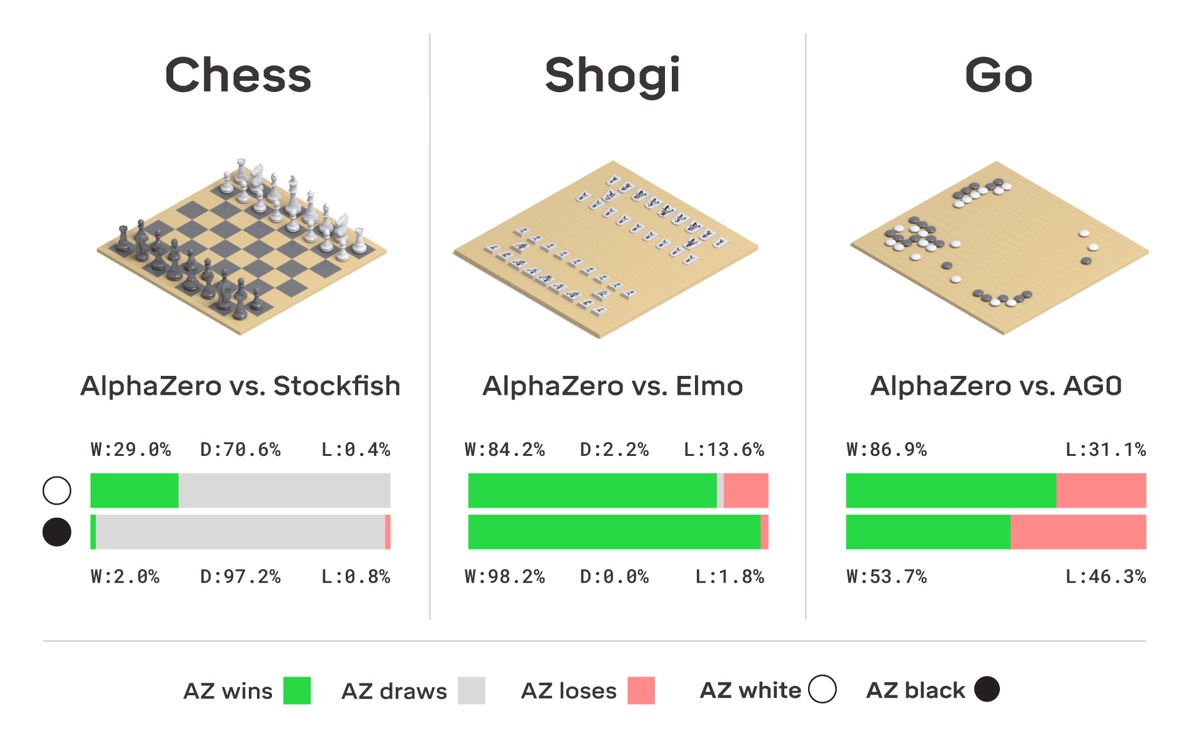
DeepMind's new AI is worthy successor to the first program to beat a human at Go.

AlphaGo PDF, PDF, Game Theory

It's able to create knowledge itself': Google unveils AI that learns on its own, Science
What's Inside AlphaZero's Chess Brain?

Why DeepMind AlphaGo Zero is a game changer for AI research

Amazing Coincidence in the Matches of Deep Blue and AlphaGo — Move 37, Game 2, by franky

AlphaZero algorithm can pick up victory moves in chess

Simple Alpha Zero
Is there an Open Source version of AlphaZero? (specifically, the generic game-learning tool, distinct from AlphaGo) - Quora

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Chess's New Best Player Is A Fearless, Swashbuckling Algorithm
Recomendado para você
-
 New AlphaZero Paper Explores Chess Variants19 setembro 2024
New AlphaZero Paper Explores Chess Variants19 setembro 2024 -
 Alphazero :: Computer-bridge119 setembro 2024
Alphazero :: Computer-bridge119 setembro 2024 -
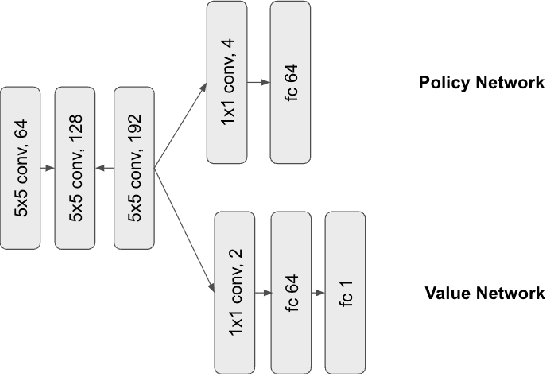 AlphaZero Gomoku: Paper and Code - CatalyzeX19 setembro 2024
AlphaZero Gomoku: Paper and Code - CatalyzeX19 setembro 2024 -
 AlphaZero from Scratch – Machine Learning Tutorial19 setembro 2024
AlphaZero from Scratch – Machine Learning Tutorial19 setembro 2024 -
GitHub - timvvvht/AlphaZero-Connect4: An asynchronous implementation of AlphaZero, a self-play reinforcement learning algorithm.19 setembro 2024
-
 How AlphaZero Works – Augmented Lawyer19 setembro 2024
How AlphaZero Works – Augmented Lawyer19 setembro 2024 -
 TLDR: When AlphaZero played Stockfish it had a 31x hardware advantage. : r/chess19 setembro 2024
TLDR: When AlphaZero played Stockfish it had a 31x hardware advantage. : r/chess19 setembro 2024 -
 DeepMind, Google Brain & World Chess Champion Explore How AlphaZero Learns Chess Knowledge19 setembro 2024
DeepMind, Google Brain & World Chess Champion Explore How AlphaZero Learns Chess Knowledge19 setembro 2024 -
 Creative' AlphaZero leads way for chess computers and, maybe, science, Chess19 setembro 2024
Creative' AlphaZero leads way for chess computers and, maybe, science, Chess19 setembro 2024 -
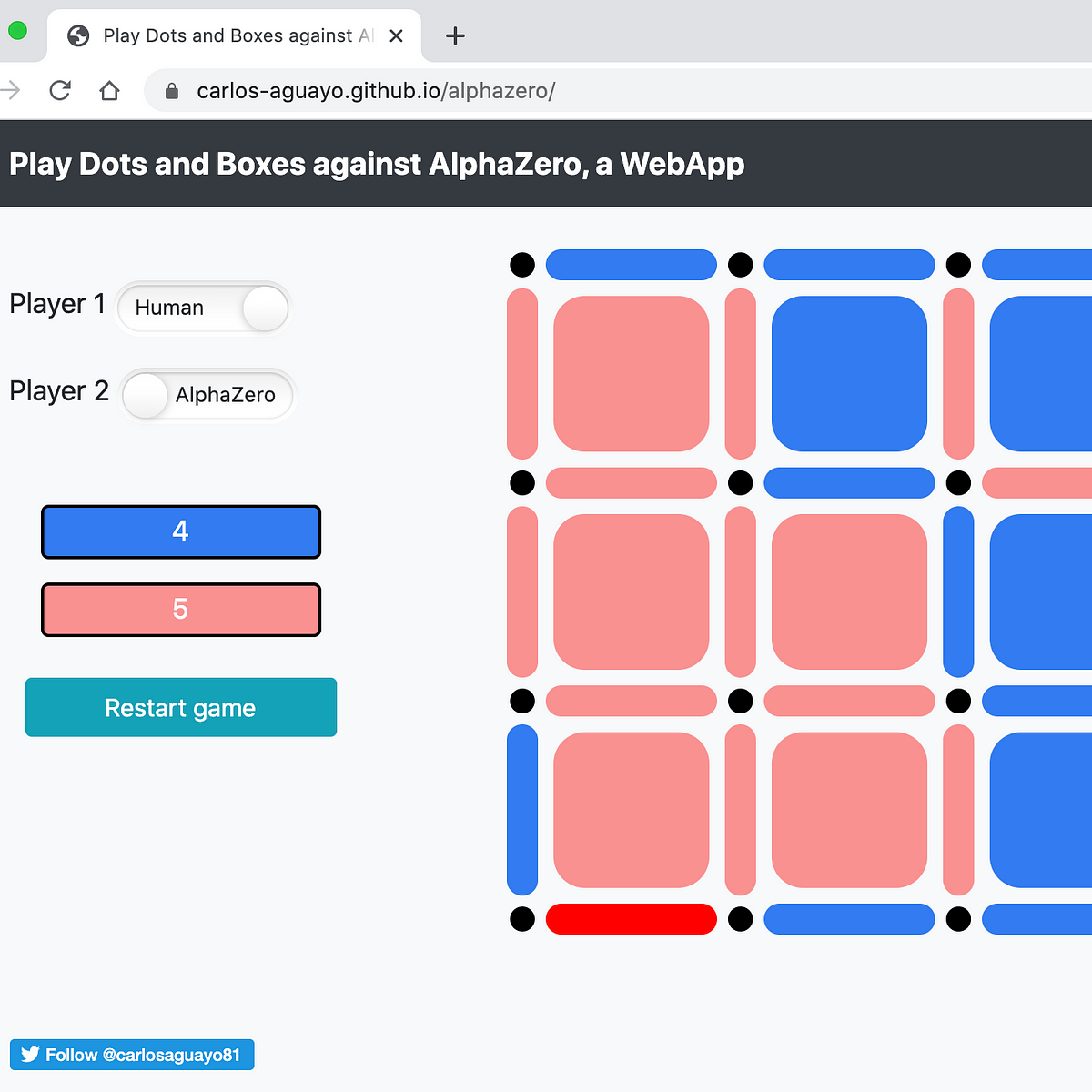 AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript, by Carlos Aguayo19 setembro 2024
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript, by Carlos Aguayo19 setembro 2024
você pode gostar
-
 Sign in to My Kohl's Card to Make a Payment, My Kohls Credit Card Login19 setembro 2024
Sign in to My Kohl's Card to Make a Payment, My Kohls Credit Card Login19 setembro 2024 -
 34 melhores brincadeiras para WhatsApp - Tediado19 setembro 2024
34 melhores brincadeiras para WhatsApp - Tediado19 setembro 2024 -
 Spy Classroom anime announced - Niche Gamer19 setembro 2024
Spy Classroom anime announced - Niche Gamer19 setembro 2024 -
 Jannik Sinner cheered on by orange-clad fans during Italian Open19 setembro 2024
Jannik Sinner cheered on by orange-clad fans during Italian Open19 setembro 2024 -
 Speed Auto Clicker - Product Information, Latest Updates, and19 setembro 2024
Speed Auto Clicker - Product Information, Latest Updates, and19 setembro 2024 -
Camiseta Basica Camisa Roblox Boy MMORPG Gamer Game Unissex Geek19 setembro 2024
-
 Tay Training (taymartintlm) - Profile19 setembro 2024
Tay Training (taymartintlm) - Profile19 setembro 2024 -
 🔴 BOLOGNA X FROSINONE – AO VIVO19 setembro 2024
🔴 BOLOGNA X FROSINONE – AO VIVO19 setembro 2024 -
 Buy STREET WEAR DROP PSYCHOMOD in Lyonk19 setembro 2024
Buy STREET WEAR DROP PSYCHOMOD in Lyonk19 setembro 2024 -
 University of Miami on X: Graduating with a Doctorate in Physical Therapy this week, @umiamimedicine student Stefanie Cohen doubles as record-holding powerlifter. #umiami #canegrad / X19 setembro 2024
University of Miami on X: Graduating with a Doctorate in Physical Therapy this week, @umiamimedicine student Stefanie Cohen doubles as record-holding powerlifter. #umiami #canegrad / X19 setembro 2024
