RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 19 setembro 2024

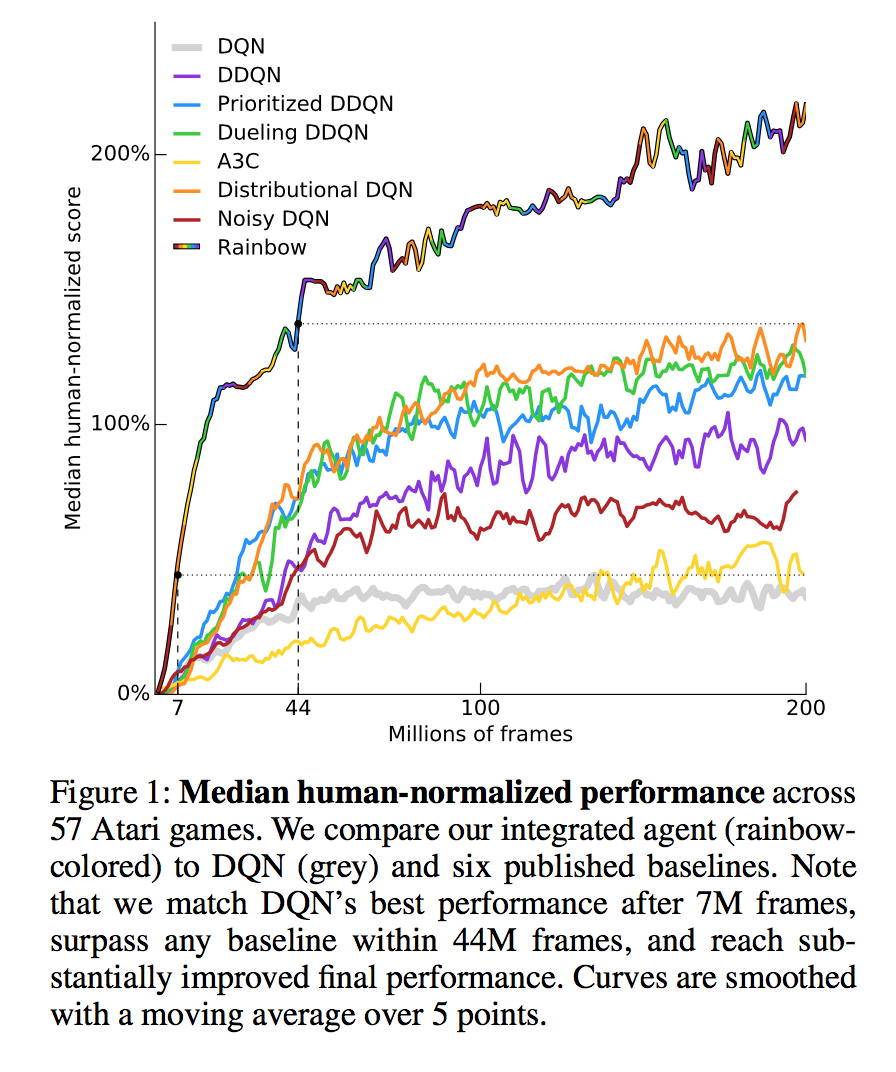
In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
Warm-start Reinforcement Learning Mobility Science Automation and Inclusion Center

Memory-based Reinforcement Learning
Applied Sciences, Free Full-Text
Johan Gras (@gras_johan) / X

Kristian Kersting
RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
All Categories - Miles Brundage
All Categories - Miles Brundage

Scheduling UAV Swarm with Attention-based Graph Reinforcement Learning for Ground-to-air Heterogeneous Data Communication
Recomendado para você
-
 How is This Possible? AlphaZero Shows Us the Way19 setembro 2024
How is This Possible? AlphaZero Shows Us the Way19 setembro 2024 -
 How did Google's AlphaZero beat the world's best chess computer?19 setembro 2024
How did Google's AlphaZero beat the world's best chess computer?19 setembro 2024 -
 AQUACITY on X: AlphaZero's Unstoppable Journey! ♟🌟 Google's DeepMind AI has transformed the gaming world again, mastering chess in just 4 hours and taking down the champion program Stockfish 8! 🎲🏆 #AlphaZero #19 setembro 2024
AQUACITY on X: AlphaZero's Unstoppable Journey! ♟🌟 Google's DeepMind AI has transformed the gaming world again, mastering chess in just 4 hours and taking down the champion program Stockfish 8! 🎲🏆 #AlphaZero #19 setembro 2024 -
 Tree structure of the original AlphaZero algorithm and the19 setembro 2024
Tree structure of the original AlphaZero algorithm and the19 setembro 2024 -
How AlphaZero Completely CRUSHED Stockfish ( Part 10 ) #chess #gotha19 setembro 2024
-
 AlphaZero (2017)19 setembro 2024
AlphaZero (2017)19 setembro 2024 -
 From-scratch implementation of AlphaZero for Connect419 setembro 2024
From-scratch implementation of AlphaZero for Connect419 setembro 2024 -
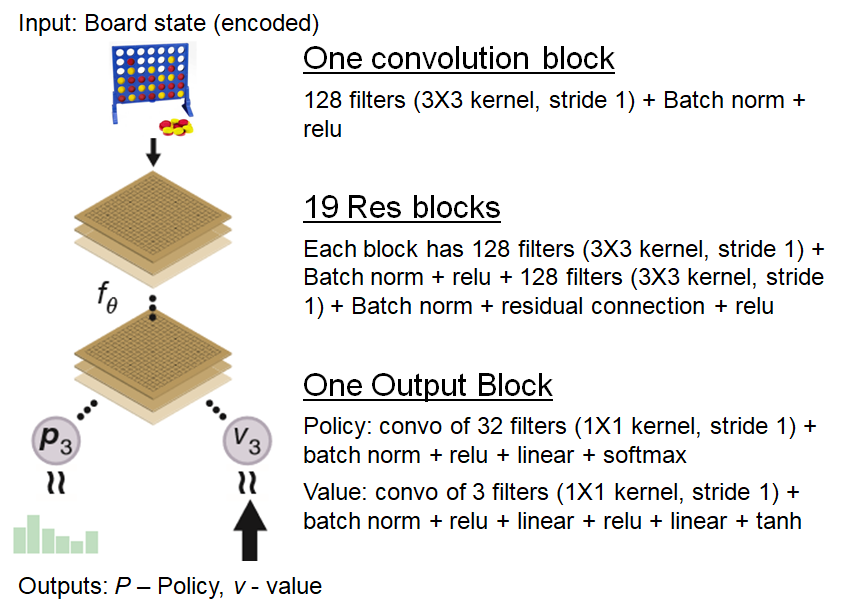 From-scratch implementation of AlphaZero for Connect4, by Wee Tee Soh19 setembro 2024
From-scratch implementation of AlphaZero for Connect4, by Wee Tee Soh19 setembro 2024 -
 AlphaZero paper discussion (Mastering Go, Chess, and Shogi) • Life In 19x1919 setembro 2024
AlphaZero paper discussion (Mastering Go, Chess, and Shogi) • Life In 19x1919 setembro 2024 -
 AlphaZero: Four Hours to World Class from a Standing Start19 setembro 2024
AlphaZero: Four Hours to World Class from a Standing Start19 setembro 2024

você pode gostar
-
 Ridge Racer Unbounded™: Drifting (sort of) Like A Boss19 setembro 2024
Ridge Racer Unbounded™: Drifting (sort of) Like A Boss19 setembro 2024 -
 Réquiem - Qué es, definición y concepto19 setembro 2024
Réquiem - Qué es, definición y concepto19 setembro 2024 -
Does anyone have any vocaloid song recommendations19 setembro 2024
-
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/7/f/6lMkcERGKr8QZecenlBQ/glbimg.com-po-tt-f-620x388-2013-04-18-csr-racing-1.jpg) CSR Racing é um jogo de corrida para Android focado em rachas19 setembro 2024
CSR Racing é um jogo de corrida para Android focado em rachas19 setembro 2024 -
 LEGO Marvel The New Guardians’ Ship 76255 6427740 - Best Buy19 setembro 2024
LEGO Marvel The New Guardians’ Ship 76255 6427740 - Best Buy19 setembro 2024 -
Pokemon Eevee Evolução de brinquedos de pelúcia Sylveon Flareon Joolaon/Umbreon/Vaporeon/Presente de aniversário para crianças19 setembro 2024
-
 Super Mario Bros. Wonder Online Multiplayer Revealed, No Online Co-op19 setembro 2024
Super Mario Bros. Wonder Online Multiplayer Revealed, No Online Co-op19 setembro 2024 -
 Novo Modo Aventura com Passe de Graça no Hill Climb Racing 219 setembro 2024
Novo Modo Aventura com Passe de Graça no Hill Climb Racing 219 setembro 2024 -
 Are Crystals Rocks? No! But That's Not All // Tiny Rituals19 setembro 2024
Are Crystals Rocks? No! But That's Not All // Tiny Rituals19 setembro 2024 -
 Promoções da Semana (Válidas de 27/12 a 02/01), XBOX BRAZUCAS, Xbox Brasil, Xbox one19 setembro 2024
Promoções da Semana (Válidas de 27/12 a 02/01), XBOX BRAZUCAS, Xbox Brasil, Xbox one19 setembro 2024