DeepMind's MuZero teaches itself how to win at Atari, chess, shogi, and Go
Por um escritor misterioso
Last updated 09 janeiro 2025

In a preprint paper, researchers at Alphabet's DeepMind detail MuZero, an algorithm that effectively teaches itself how to play Atari and board games.

DeepMind just taught AI how to win a game without knowing the rules
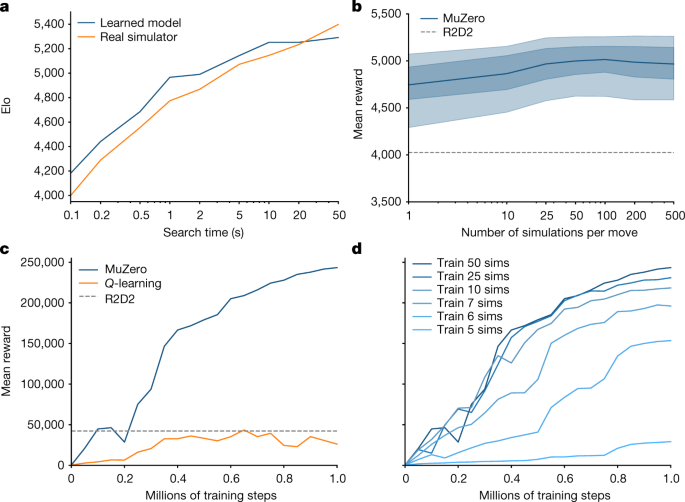
Mastering Atari, Go, chess and shogi by planning with a learned model
Is it possible for machine logic to evolve? AlphaZero taught itself to play chess and demolished Stockfish, just as some AI's create language which its programmers can't understand. - Quora

DeepMind's AI agent MuZero could turbocharge - BBC News

MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind

Want to Know the AI Lingo? Learn the Basics, From NLP to Neural Networks - WSJ

papers

MuZero - Wikipedia
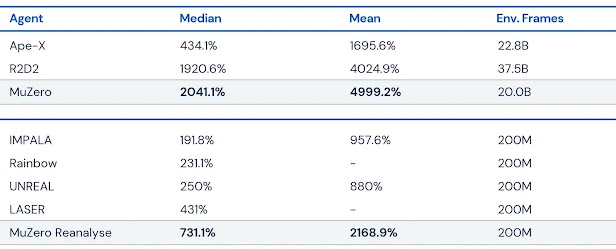
MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind

Student of Games: DeepMind AI can beat top humans at chess, Go and poker

MuZero - Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Recomendado para você
-
 Alphazero :: Computer-bridge109 janeiro 2025
Alphazero :: Computer-bridge109 janeiro 2025 -
 Leela Chess Zero: AlphaZero for the PC09 janeiro 2025
Leela Chess Zero: AlphaZero for the PC09 janeiro 2025 -
 AlphaZero - Wikipedia09 janeiro 2025
AlphaZero - Wikipedia09 janeiro 2025 -
 Stockfish (chess) - Wikipedia09 janeiro 2025
Stockfish (chess) - Wikipedia09 janeiro 2025 -
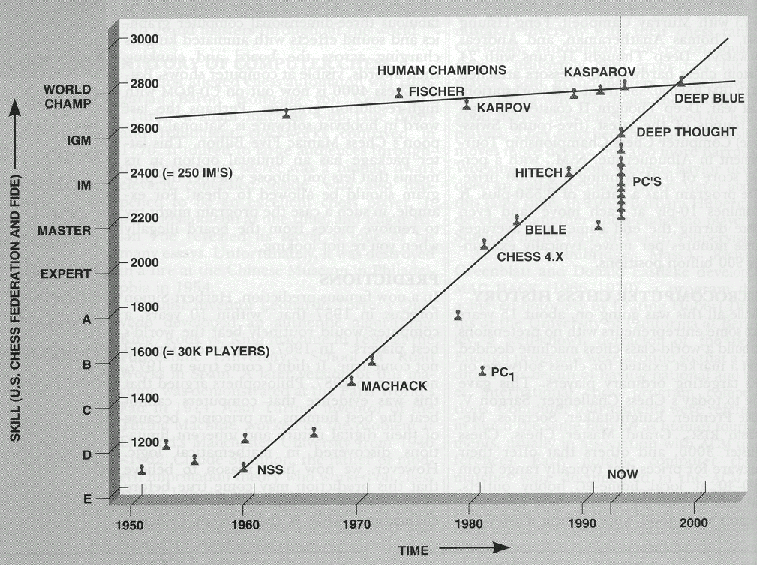 Time for AI to cross the human performance range in chess – AI Impacts09 janeiro 2025
Time for AI to cross the human performance range in chess – AI Impacts09 janeiro 2025 -
![AlphaZero vs Stockfish 8 Scaling Recreation [50% Complete] by Cscuile](https://groups.google.com/group/lczero/attach/3a45501fba376/Leela%20vs%20Stockfish%20Scaling.PNG?part=0.2&view=1) AlphaZero vs Stockfish 8 Scaling Recreation [50% Complete] by Cscuile09 janeiro 2025
AlphaZero vs Stockfish 8 Scaling Recreation [50% Complete] by Cscuile09 janeiro 2025 -
Will AlphaZero become available to the public? - Quora09 janeiro 2025
-
Is it possible that Alpha Zero will eventually solve chess? - Quora09 janeiro 2025
-
 Was Alphazero beating Stockfish BS? • page 2/3 • General Chess Discussion •09 janeiro 2025
Was Alphazero beating Stockfish BS? • page 2/3 • General Chess Discussion •09 janeiro 2025 -
 Training AlphaZero for 700,000 steps. Elo ratings were computed from09 janeiro 2025
Training AlphaZero for 700,000 steps. Elo ratings were computed from09 janeiro 2025
você pode gostar
-
Battlefield 2042 - PC EA app09 janeiro 2025
-
 What was planted in faith? Let's not Dig Up in Terraria! - Page 509 janeiro 2025
What was planted in faith? Let's not Dig Up in Terraria! - Page 509 janeiro 2025 -
 ALKISTA 48 Pcs Tetra Tower Balance Stacking Blocks Game, Board Games for 2 Players+ Family Games, Parties, Travel, Kids & Adults Team Building Blocks09 janeiro 2025
ALKISTA 48 Pcs Tetra Tower Balance Stacking Blocks Game, Board Games for 2 Players+ Family Games, Parties, Travel, Kids & Adults Team Building Blocks09 janeiro 2025 -
 Assistir Maou Gakuin no Futekigousha 2 Episódio 12 Legendado (HD) - Meus Animes Online09 janeiro 2025
Assistir Maou Gakuin no Futekigousha 2 Episódio 12 Legendado (HD) - Meus Animes Online09 janeiro 2025 -
 Control fruit, Video Gaming, Gaming Accessories, In-Game Products09 janeiro 2025
Control fruit, Video Gaming, Gaming Accessories, In-Game Products09 janeiro 2025 -
.jpg?ph=true) Tom Clancy's Splinter Cell Conviction (Xbox 360) • Price »09 janeiro 2025
Tom Clancy's Splinter Cell Conviction (Xbox 360) • Price »09 janeiro 2025 -
 How can you break your controller like this ☠️ : r/playstation09 janeiro 2025
How can you break your controller like this ☠️ : r/playstation09 janeiro 2025 -
Triciclo Tico Tico Pets Rosa Motoca Infantil Magic Toys 281109 janeiro 2025
-
 Shindo Life Shindai Valley codes (December 2023) — private servers09 janeiro 2025
Shindo Life Shindai Valley codes (December 2023) — private servers09 janeiro 2025 -
 Árbitro da Confederação Brasileira de Futebol (CBF) apita a final do Veterano de Futebol neste sábado (26)09 janeiro 2025
Árbitro da Confederação Brasileira de Futebol (CBF) apita a final do Veterano de Futebol neste sábado (26)09 janeiro 2025
